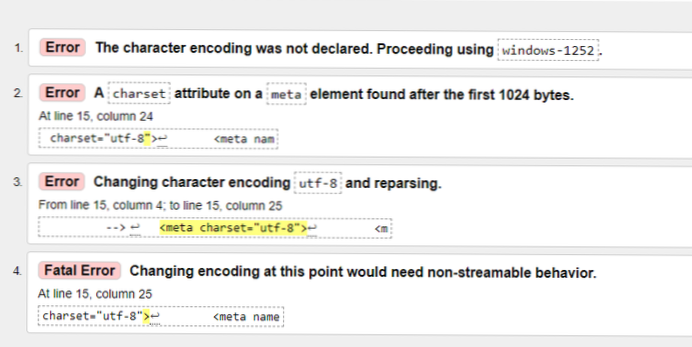
- Come posso eliminare l'errore UTF-8??
- Che cos'è l'errore UTF8??
- Come cambio la codifica in UTF-8?
- Come viene memorizzato UTF8??
- Come posso risolvere i problemi di Unicode??
- Quali caratteri non sono consentiti in UTF-8?
- Cosa significa UTF-8 in HTML??
- Perché UTF-8 ha sostituito l'ascii??
- UTF-8 è lo stesso di Ascii??
- Qual è la differenza tra ANSI e UTF-8?
- Perché viene utilizzato UTF-8??
- Cosa significa UTF-8?
Come posso eliminare l'errore UTF-8??
2 risposte
- usa un set di caratteri che accetterà qualsiasi byte come iso-8859-15 noto anche come latin9.
- se l'output deve essere utf-8 ma contiene errori, usa errors=ignore -> rimuove silenziosamente i caratteri non utf-8 o gli errori=sostituisci -> sostituisce i caratteri non utf-8 con un marcatore di sostituzione (di solito ? )
Che cos'è l'errore UTF8??
UTF-8 è il formato di codifica dei caratteri dominante sul World Wide Web. Questo errore si verifica perché il software che stai utilizzando salva il file in un diverso tipo di codifica, come ISO-8859, invece di UTF-8. Esistono diverse soluzioni che puoi utilizzare per modificare il tuo file con la codifica UTF-8.
Come cambio la codifica in UTF-8?
Fare clic su Strumenti, quindi selezionare Opzioni Web. Vai alla scheda Codifica. Nel menu a discesa Salva questo documento come: scegli Unicode (UTF-8). Fare clic su OK.
Come viene memorizzato UTF8??
Quando il software che legge UTF-8 incontra un byte che inizia con 1, conta quanti 1 seguono prima di incontrare uno 0. ... Quindi un byte della forma 110xxxxx dice che i primi cinque bit di un carattere Unicode sono memorizzati alla fine di questo byte e il resto dei bit arriva nel byte successivo.
Come posso risolvere i problemi di Unicode??
Il primo passo per risolvere il tuo problema Unicode è smettere di pensare al tipo< 'str'> come stringhe di memorizzazione (cioè sequenze di caratteri leggibili dall'uomo, a.K.un. testo). Invece, inizia a pensare al tipo< 'str'> come contenitore di byte.
Quali caratteri non sono consentiti in UTF-8?
Nota che un byte-order mark (BOM) U+FEFF, noto anche come spazio senza interruzioni di larghezza zero (ZWNBSP), non può apparire non codificato in UTF-8 — i byte 0xFF e 0xFE non sono consentiti in UTF-8 valido. Un ZWNBSP codificato può apparire in un file UTF-8 come 0xEF 0xBB 0xBF, ma il BOM è completamente superfluo in UTF-8.
Cosa significa UTF-8 in HTML??
charset=UTF-8 sta per Set di caratteri = Unicode Transformation Format-8. È una codifica senza perdita di ottetti (8 bit) di caratteri Unicode. Questi dovrebbero far luce sulla comprensione nello sviluppo Web e nello scripting.
Perché UTF-8 ha sostituito l'ascii??
L'UTF-8 ha sostituito ASCII perché conteneva più caratteri di ASCII che è limitato a 128 caratteri.
UTF-8 è lo stesso di Ascii??
Per i caratteri rappresentati dai codici dei caratteri ASCII a 7 bit, la rappresentazione UTF-8 è esattamente equivalente all'ASCII, consentendo una migrazione trasparente di andata e ritorno. Altri caratteri Unicode sono rappresentati in UTF-8 da sequenze fino a 6 byte, sebbene la maggior parte dei caratteri dell'Europa occidentale richieda solo 2 byte3.
Qual è la differenza tra ANSI e UTF-8?
ANSI e UTF-8 sono due schemi di codifica dei caratteri ampiamente utilizzati in un momento o nell'altro. La differenza principale tra loro è l'uso poiché UTF-8 ha quasi sostituito ANSI come schema di codifica preferito. ... Poiché ANSI utilizza solo un byte o 8 bit, può rappresentare solo un massimo di 256 caratteri.
Perché viene utilizzato UTF-8??
Perché usare UTF-8? Una pagina HTML può essere solo in una codifica. Non è possibile codificare parti diverse di un documento in codifiche diverse. Una codifica basata su Unicode come UTF-8 può supportare molte lingue e può ospitare pagine e moduli in qualsiasi combinazione di tali lingue.
Cosa significa UTF-8?
Nozioni di base su UTF-8. UTF-8 (Unicode Transformation-8-bit) è una codifica definita dall'International Organization for Standardization (ISO) in ISO 10646. Può rappresentare fino a 2.097.152 punti di codice (2^21), più che sufficienti per coprire gli attuali 1.112.064 punti di codice Unicode.
![Creazione di categorie, pagine e post su Dashboard [chiuso]](https://usbforwindows.com/storage/img/images_1/creating_categories_pages_and_post_on_dashboard_closed.png)